Advanced Git Use
by Alessandro Rubini
Reproduced and translated with permission of Linux & C, Edizioni Vinco.
The git package was originally written by Linus Torvalds,
and was later maintained by other developers under the lead
of Junio Hamano. The program is being adopted by an ever-increasing
number of projects, from the kernel and U-Boot to Xorg
and busybox. It belongs to the class of distributed version
control systems.
A first introduction to using the package was published on this
same magazine by Rodolfo Giometti. This article introduces to some more
advanced features, that are needed to interact with complex products, while
trying to uncover the ideas used within the program.
Box 1 summarizes the most important
commands of git, as quick reference for the least expert readers.
Box 1 - Most Common Git Commands
The following list shows the most important commands for git
users. Command arguments are not shown as there often are several
alternate uses, with different argument lists:
- git clone: make a local copy of a remote repository
- git fetch: download remote updates to a local branch
- git branch: create, rename, delete tree branches
- git checkout: extract files for a specific version or branch
- git add: prepare to commit one or more file that have changed
- git commit: commit a patch to the local repository
- git rebase: move the base of a branch, connecting it elsewhere
- git log: show history of a branch or a file
- git diff: print differences between versions or branches
- git merge: merge branches, while keeping both histories
- git pull: fetch and merge a remote branch
Distributed version control systems are more and more widespread;
git is not the first and won't be the last one. The ideas
described in this article are also present, in various measures, in
other packages, like mercurial; the aim of this text is not showing
how git is superior to other tools, but rather show interesting
features that can be useful in other contexts as well. We talk about
git because it is widely adopted.
To avoid ambiguity, we will never use the word tree to
refer to a directory with files and subdirectories. The word in
the git context is best reserved to a development history
of a package, with all its ramifications.
The problem of verification
One of the most common problems in managing big
software projects is the imperfect matching of the working directory
of different programmers: developers often remove completely
their local copy, to restart
from a known archive or repository; this is common, but unpleasant.
The same problem occurs when there are collisions while applying a patch,
or the source file was damaged by some mishap.
Moving tens or hundreds of megabytes to recover a source package
is certainly not a nice experience, verifying whether one's copy is
exactly the same as the copy of a different developer is even worse
if you can't directly transfer the files.
The solution to both such problems is the identification of every
object, within git, with a control code: a number that is
derived from the whole amount of related data through a
non-invertible mathematical algorithm. Such control code, called
hash or message digest describes (or summarizes) the datum
or data set, but the math makes it impossible (or very unfeasible)
the creation of a different data set with the same hash.
The algorithm used in git is SHA1 (Secure hash
algorithm 1) which returns a 160-bit long hash.
The number is usually represented as 40 hex digits.
For example, if you want to group all files called
COPYING in your system that are verbatim copies
for the same license file, you can issue the command:
locate COPYING | xargs sha1sum | sort
Within git, thus, each individual file, each directory,
each commit is identified by its own hash value. A specific point in
the development history of a package cannot be referenced by a sequential
version number, but rather by a unique 160-bit number. An object of
type commit includes a reference to the contents of the
directory it represents, the commit message and the hash of the previous
commit. If two programmers have the same commit, they know for sure
that they are accessing the same source package. During technical discussions
on public mailing lists, referring to code or patches using the hash value
or an abbreviation thereof, is common practice.
Box 2 - Uniqueness of hash codes
Message digest algorithms warrant that the hash they return
is unique by statistical probability. The most common such algorithms
are SHA1 and MD5, which return values with a uniform distribution over the
value space. By recalling that 2^10 is roughly equivalent to 10^3,
we can say there's a chance of 1 in 4 billions for two 32-bit hashes
to be equal. The number is on the order of 10^38 for 128-bit MD5 hashes
and 10^48 for 160-bit SHA1 values.
Even with 1 million files, the chance for any two of them to
feature the same SHA1 hash is 1 in 10^36, while for a billion files
the chance is 1 in 10^30. 10^30 is roughly the number of sand grains
in the mass of the whole earth; you can hardly say the hash is
not unique.
Hash algorithms are designed so that the difference of even
a single bit in the input data will affect all output bits. So
in practice to identify a file you can use a few hex digits of the hash, and
still be sure enough about not picking the wrong file. Thus,
git accepts abbreviated identifiers, as long as the abbreviation
is unique within its database. Thus, if you ask for an abbreviated
for of the hash, git shows just 7 hex digits.
Even within a project with 1 billion objects, like the kernel,
the chance for a 7 digits code to be ambiguous is very low.
When picking objects within a project, you don't need that your hash
to be globally unique; it's enough if is unique within the project: when the
7-digit code is ambiguous, git will show 8 digits or more,
in order to solve the local ambiguity; it's somehow like what happens at school:
teachers call students by surname, and in case of ambiguity they add the
initial of the name, or more letters if needed. Please note that
internally git is always using the hashes in their entirety.
We could test the idea by checking the SHA1 hash of Linux-2.6.30
as extracted from a git repository and that of the official tar
file. To do this we need to use git cat-file to look into
the relevant commits:
bash$ cd linux-2.6.git
bash$ git checkout v2.6.30
HEAD is now at 07a2039... Linux 2.6.30
bash$ git cat-file commit 07a2039 | grep tree
tree 0cea46e43f0625244c3d06a71d6559e5ec5419ca
bash$ tar xjf linux-2.6.30.tar.bz2
bash$ cd linux-2.6.30
bash$ git init
bash$ git add .
bash$ git commit -m "from tar file"
Created initial commit 7a6212e: from tar file
bash$ git cat-file commit 7a6212e | grep tree
tree 0cea46e43f0625244c3d06a71d6559e5ec5419ca
Box 3 - The git cat-file command
Since git records all of its objects in compressed format,
blessing them according to the SHA1 hash, the tool offers
the command "git cat-file" in order to print to stdout
(like cat, as the name suggests) the contents of an object.
The command receives two arguments: the object's type and its SHA1.
The command returns the contents of the file in case of blob objects,
but for commit objects its output is a short text that includes
the log message, the author's name, date of the commit in Unix
format and the SHA1 codes of both parent and tree. The former
is the previous commit in history and the latter is the directory of
files described by this commit.
The user interface for git cat-file isn't what you'd define
friendly. For example, if you git cat-file a tree
object, you'll get a binary file sent to the terminal. This happens
because cat-file is one the low-level commands, used by
other git commands to get their work done.
In git documentation, low-level commands like this one are
called plumbing, while the ones meant to be typed by real users
are called porcelain -- the user interface that seats above
plumbing, where eventually the user sits.
Commands listed in box 1, for example, are part of the
porcelain set.
As apparent, the tree object contained in the two commits is the
same one. This is enough to demonstrate that the two file sets, 400MB each,
are identical even we retrieved them in a different way.
With "git ls-tree" you can check what the internal git
representation for such tree objects is; just like in a Unix directory, the
object includes names and identifiers for other objects. In this listing,
objects of type blob are normal files, those of type tree
are subdirectories. Just like a directory associates names to
their inode numbers, which are unique within the filesystem,
a tree object in git associates names to their hashes, which
are unique within the database (and globally, but this is irrelevant here).
The content of each object, then, is stored
in a file whose name is exactly the associated SHA1 value. A side effect
of this approach is that objects in git are immutable: every modification,
even of a single bit, creates a new object with a new hash and, thus,
a new file.
A secondary effect, and not a trivial one, of massive use of
hash codes is the easiness in signing. If the author wants to
sign a specific version of the software package, thay can just sign
the SHA1 that represents the last commit. This testifies about
the whole development, because the commit you signed
includes the whole directory and the parent commit, as already noted
(which in turn includes its tree and its parent, and so on).
Signing such hashes is done with the usual asymmetric-key tools.
Thus, if a developer signs a specific commit, whoever gets hold
of the same commit or the tree it refers to, they can be certain about
source code integrity by just verifying the signature, even if the sources
come from untrusted sources. The only components that you
need to trust are the tools that create and check SHA1 hashes,
i.e. git, gpg and other tools that are usually part
of the operating system. You can usually trust them because they
are signed by the relevant package maintainers.
Creating a branch
The main difference between distributed and centralized
version control system is in how easy (or not) creating
branches is.
Personally, as a git user, I find that the concept of branch
is very similar to the concept of tag, and I hope this idea won't
upset those who know the internal representation of the two. We may
say that a branch is like a tag because just like "git tag
v1.0" binds a meaningful name to the SHA1 name of the current
development status, the command "git branch
1.0-fixes" binds a new symbolic name to the current status.
Both such names can be used in retrieving the current version
by calling "git checkout <name>".
But a branch name is a moving tag: whenever some change is
committed, the tag name will keep
referring to the original SHA1, while the branch name will move, following
the development.
Unless you are using a detached head, which is not common and
not covered here, the current source status on the disk (the HEAD
position, in git wording and case) corresponds to one of the development branches.
Thus every commit operation is actually growing a branch.
The name of the main branch, the one called trunk by other packages,
is master. The master branch is created when you make the
first commit ever, and it is not a special name at all. All branches
are managed in the same way; you can rename any branch you like or remove
any branch you dislike,
including master. Deleting a branch is like deleting a tag: all
the git objects remain in the repository and you can retrieve them if
you know their SHA1, at least until you garbage collect, a topic
not covered in these pages. When you delete a branch, git
tells you what hash it was, so you can undo the deletion if you removed
it in error.
To move from one branch to another you can use the command git
checkout <branch>, but the program refuses
to perform the task if there are yet-uncommitted local modifications,
to prevent loosing your work in unexpected ways.
The idea that a branch is just a label, without any reference to where
and how it got detached from the original branch, is a remarkable one:
if during development you get to a dead end, you can always create
a new branch from some place in past history and try a different way to
attack your problem; if such new way turns out to be the winning one,
you can delete the initial branch without any effect on the new branch.
Deleting a branch is like deleting a tag: the only effect is you can't
reach the associated status with its human-readable name any more. The fact
that a new branch was spun from the one now deleted is irrelevant:
the tip of the branch that you preserved identifies the whole history,
from project inception up to there, without any reference to other branches
or splitting points.
Obviously, you can ask about the differences, or the log,
between your head and another branch, for example the one you split
from. But branches refers to no other branch, only to their past
history; so, to compare branches, the system scans back the
history of both branches until it finds a common commit, a SHA1 value
that is common to both branches. This match in hash values is the
only indication that the two branches have a
common ancestor, and such ancestor can now be used as a starting point
to perform the diff or log you asked for.
Such flexibility in branch management can easily lead developers
to have dozens of branches in their tree; you must therefore be careful
in choosing branch names, and remember to delete inactive branches,
or move them to another git tree; otherwise, you'll find it hard to
track the various aspects of your work.
Box 4 - Version numbers used in git
The identifiers used in git command lines, to name commits or
other objects, fall in several categories. The most useful and most
used are:
- SHA1 codes: a 40 digit hexadecimal string
- SHA1 abbreviations: the leading part of a SHA1 code, as long as it
is not ambiguous
- a symbolic name: tag or branch name
HEAD: the last commit in the current branch- name^: the commit preceding name
- name~n: n commits back from name
Some commands can act on intervals, like git log
or git format-patch. The most common expression for intervals
is "v1..v2", that represents all
commits that are reachable from v2 but not from v1.
Each commit allows to find back all of its past history, so
reachable refers to an ancestor of the specific version.
Therefore, the notation .. identifies the history from
v1 to v2, if v1 is ancestor of v2, or
from the splitting point up to v2 if the versions are in
different branches.
Cleaning up and reordering the code history
No developer usually writes working code from scratch
-- there are a very few exceptions, but we can't make tools
that only work for them. Moreover, few people can
afford devoting to a single
problem until it is completely solved, while ignoring other issues.
The net result of these internal and
external limits in the development activity, is that in practice everyone
writes code in a fuzzy way. On one hand we tend to add and then
remove diagnostic messages or other tricks one may be ashamed of, on
the other hand the available time is split among several issues, moving
between them and temporarily abandoning each of them before it is
completely solved, including the issues that will eventually be fixed.
History in a working branch is thus often quite a mess of changes:
commits about different logical problems mix up in a seemingly random
way, and some diagnostics code fragments are added and then removed
soon after. Before such mess is delivered to the net and becomes part
of the official history of computer science, the author needs to clean up.
This means changing the relative order of the commits, collapsing several
work steps in a single patch that fixes a bug or adds a feature in a
single step, removing irrelevant modifications.
The tool git offers to this aim is "git rebase -i", where
the i means "interactive". The command allows rewriting the
history of the current branch, starting from a specified version. For
example, "git rebase -i HEAD~10" allows reordering,
collapsing and dropping anything since 10 commits ago. To do that, git
fires a text editor, opening a file that includes both the list
of the commits in your recent history, one
per line, and the instructions about how to edit it. The options are
well described, so I won't repeat it here.
If you want to save the current status before daring a reordering step,
you can
simply create a new branch and try rebasing that one. Otherwise,
you might just take note of the original hash, or make a temporary tag.
It's always possible,
at a later time, to ask git what are the differences between the old and
the new branch, using git diff from the old branch, hash or tag..
Moving branches between trees: fetch, rebase, cherry-pick
The history of a package, including all branches, is hosted in
the .git folder within the package itself, it is nothing more
than a local copy. A common need, therefore,
is moving branches between different trees, both within the same disk and
across the network.
To copy objects between different trees, git uses the fetch
subcommand. while working on the receiving side, you tell on the command
line what remote repository and branch you want to download from, as well as the name
of the local branch where commits should be placed. The program retrieves
the history of the remote branch and only copies the objects that are
missing from the local tree. During the copy, any remote tag on
the relevant branch is reproduced locally.
When you git fetch,
the name you use for the local branch may already exist in your
repository. Git will
create the branch if it doesn't exists; otherwise it will grow the existing
local branch. In this case the local branch should be an ancestor
of the branch being fetched, or it wouldn't be possible to copy the
objects while preserving the local commits. When this happens,
the error is "rejected: non fast-forward". Therefore,
fetch can only grow a branch, without changing it in any way
unless you explicitly force this behaviour.
Usually, the "small programmers" keep a local copy of the development branches
by "big programmers", and they periodically git fetch to
follow development of the upstream package. A local branch that
is used to follow remote development is called remote
tracking branch or remote branch for short. If you
are modifying an external project, you'll likely create a new local branch
that hangs off the "remote tracking" branch.
The fetch command is used in this way:
git fetch id-remote-tree source-branch:target-branch
The remote tree may be a pathname, a remote folder specified
in ssh format or a URL, either http:// or
git://. There may be even more forms I don't know about.
Please note that all branches of a tree are local, even the ones called
"remote". All information managed by git is included in the .git
folder of your working directory, and this is a design choice. A branch may
be remote tracking or not according to how it is used.
It is possible, to simplify your command lines, to
preset your preferred arguments for
specific remote trees in your .git/config file.
After you worked on a local branch, spun out of a remote-tracking one,
a further fetch performed on the remote branch will lead to split branches:
your local branch and the remote one have different head commits, even if
most of their history is in common.
You'll thus frequently need to move the local branch in order to have it
rooted in the current tip of the remote one. This operation is
called rebase. To perform a rebase you need to be on the local
branch; the command is just "git rebase <otherbranch>".
Git does the following work: it identifies the most recent common
commit, it rewinds all local commits after that forking point, it
applies the commits that lead to otherbranch and finally re-applies
the ones that have been rewound, managing possible conflicts.
Any commit that matches a commit in the other branch is automatically
discarded, so most commonly no conflict happens at all.
If you think about it, the "rebase -i" already
described is similar. In the most common case you interactively
rebase on an ancestor of your commit, as shown,
but you can as well use -i when rebasing to a
different branch.
If compared with creating an applying a set of patches,
a rebase operation is much more powerful and straightforward.
Besides, git The tool can use a lot of context,
so you get fewer conflicts and issues with a rebase than if you
created and applied patches. The involved algorithms
are called 3-way merge and octopus merge, and they
are the state of the art in this area.
Another common requirement during development is importing into a branch
some code fragments that already exist in another branch. The
command git cherry-pick allows to choose and pick the commits
you want, one at a time, and apply them to the head of your current branch.
The command is very useful when you have good commits in an
experimental branch, so you can selectively apply them to your
"good" branch. Also, you can test individual features your fellow developer
pushed to their own branch by applying them one at a time to your own branch.
Conflict handling
In all situations where several people a developing concurrently,
one of the most common problems is conflict handling. A conflict
happens when you try to apply a patch to a code fragment, but that
fragment is not what you expect it to be, because some other patch
modified it. The two
changes (your own and the one already applied) start from the same code but they are not compatible, and
cannot be merged automatically. A conflict may also happen within
the same tree, during a merge (not covered here) or a rebase,
whether interactive or not. For example, a conflict may happen
when you reverse the order of two patches, if one patch renames
a variable and the other changes code that uses that very variable.
The later patch can't be applied to
the original code, because it would modify lines that didn't exist
when the variable was using the old name.
When a conflict happens, git reports it in its messages and
stops the rebase operation, leaving the so-called "conflict markers"
in the source file. Such markers are the
usual <<<<<, =====
and >>>>> lines. The user is then expected
to solve manually the issue and then "git
add" the fixed files before continuing the merge or
rebase operation (with commands such as"git rebase
-continue"). As an alternative, the user can abort
the whole rebase with "git rebase
--abort". Before you explicitly call
git add, the conflicting file is not saved in the database as
a git object; this prevents most common errors where you would
commit the conflict markers.
Unlike CVS, git only finds conflicts when merging files that are
already known to it, so there is no information loss: both files
are still there. With CVS
and some other centralized version systems, the conflicts happen
between a local version and a file recorded in the repository. The
program in this case adds the conflict markers in the local file,
so the user won't have the original local file any more, and hand-editing
is the only possible way out. With git, the local file modified
by the markers is just a temporary copy, which is considered derived
from two parent files, both known to git. To express this
dual-parent situation, the git diff command uses a special
output format in this case, to show separately the differences of
the descendant from both ancestors at the same time. It takes some
time to get accustomed to this new format, but with some practice
you'll appreciate the usefulness of such information.
In conflict management it is helpful, once again, that git
records history as immutable objects. Even in the most horrible
source corruption, you can recover a good versions to restart from,
ignoring the result of the erroneous operation. If you tried
a merge or rebase hoping it would succeed, but then it fails miserably and
you have no time to fix the conflicts, you can just checkout one
of the original branches: all the files ridden with conflict markers
will just be deleted, together with the files whose merge succeeded.
Another mistake that may happen, is making a local modification to
a remote-tracking branch. In this case, a later git pull
will perform a merge, and the local branch will feature an incorrect history,
and your identifiers for the remote commits won't match upstream
any more, because the commits were applied to a different local tree. Sometimes
conflicts may arise, but they are the wrong way: instead of being unable
to apply the local patch to the upstream code, git tried to apply the
upstream patches to the local development.
The solution here is relatively easy: you can rename your branch
and repeat your fetch or pull: no significant data transfer will
take place, because ypu repository already downloaded them;
but you'll get a new, correct, remote-tracking branch.
Later on, you can delete the previous branch, or cherry pick
some local commits from it, or checkout one of the local commits
in its history to rebase it to the current remote branch.
Code exchange through email
After a developer has cleaned up the code to make it acceptable,
after you rebased to the new upstream version and after you solved any
conflict, the next step is usually publication, sending the patches
to maintainers. The command "git format-patch" is
used to create in the current directory one file for each commit,
starting from the version named on the command line up to the tip
of the current branch. The name of such file starts with a
4-digit number, from patch 0001- onwards,
so they appear properly ordered when you name them with wildcards
on the command line (i.e. *.patch or otherwise).
The files git format-patch creates are laid out like email
messages, with all the headers. According to the options you gave to the
command, messages may include all information needed to be identified
as an email thread, if sent as-is. If you want to contribute your work to
discussion lists for the relevant package, you can simply send those
messages. If your email client changes messages in an unpleasant way
(like breaking long lines or encoding in some non-plain-text MIME
representation) you can run git send-email directly. This
however assumes some more configuration of the git package, because you
must tell it how to actually send out the messages.
At the other side of the net there's people who need to apply
locally the patches they received by email. To do that they simply
need to run git am (apply mailbox). The command applies
the patches and reproduces the log message in the branch where it runs,
preserving authorship and other attributions. If the current commit
at the recipient's place is not the same as what the original poster
intended, the program will
apply the patch using the same techniques (and the same limits) as
the patch command, not being able to run
a 3-way merge technique. If a conflict happens, usually upstream
maintainers discard the contribution and send back a terse and cold
message to the original poster: "please rebase and resubmit".
Actually, a rebase step can use the whole history to automatically fix
conflicts, so it's really easier (globally) for you to rebase and
resubmit than for them to guess the right fix for a conflict.
git format-patch is able to detect file renames or
"copy and sliglty edit" situations, so it reports this information
in its output. For this reason,
the patch command is not always able to work as git
am. But besides renames or copies, the two diff formats are the same;
in those special cases, however, the git format is more compact and more
readable than the standard diff output (i.e. patch input), at
least until the new feature will be added to the two Unix commands.
Figura 1 - gitk
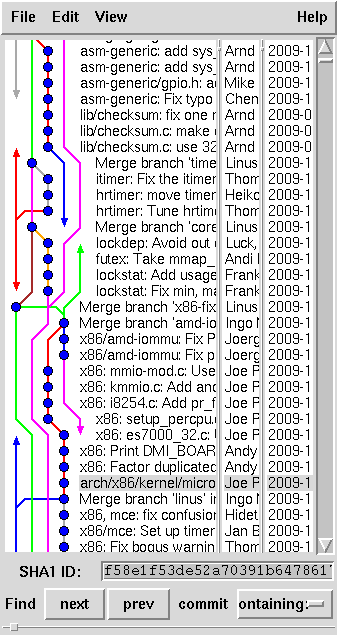
In addition to the command line, which remains the preferred interaction
tool for developers, there are some graphic tools for git users, which
are useful to both understand how a projects' history evolved, and
navigate among the various development branches.
The figure shows a window of gitk (written in Tcl/Tk). Another
approach to visualization is that of gitweb, which is usually
installed on the servers that offer source code through git.
To probe further
The git package is distributed together with extensive
documentation, as man pages (man command). For each subcommand
you find a manual page whose name begins by git-,
so for example you can invoke "man git-fetch".
This convention reflects the origins of git, when each subcommand
was actually a standalone command (with a dash in the name); but it
also allows to split a big corpus of documentation into useful
parts, whereas a single man page would be unmanageable. The main
page, "man git" is available nonetheless, and brings
introductory and general information.
Something more introductory, designed for beginners, is
gittutorial(7) (i.e., the gittutorial man page
in chapter 7 of the manual), and its follower
gittutorial-2(7), which goes to more depth. Other
manual pages that can be useful are listed in the SEE ALSO
section of git(1).
The official project site is git.or.cz, and includes
among other things an interesting "git for svn users", and other
course material, within http://git.or.cz/course/.
The http://www.youtube.com/watch?v=4XpnKHJAok8 video
is a recording of Linus Torvalds talking about git to Google technicians.
It's more like informal chatting than a technical presentation, but it is
quite interesting nonetheless.
Box 5 in this page briefly lists other git
subcommands that I originally planned to describe as useful or otherwise
interesting; detailed information about such tools can be found elsewhere,
as hinted in this section.
Box 5 - Other important subcommands
This box lists other git commands that are not covered in this
article, but that I suggest studying if you want to become a serious
git user. Some have been touched in riquadro 1.
- merge: merge two branches, This differs from rebase
as it doesn't create new commit objects but moves existing
ones into the current branch (well, somehow...). The command is most
used by project coordinators and not by us humans.
- pull: fetch and merge at the same time:
several documents say this is the preferred way to download external
branches. While this is definitely the right tool for maintainers,
being a plain user I prefer fetch which never fails, as
described in this text, because it does no merging.
- push: if you maintain a git tree which is published on the
net, this command allows to push your commits from the working directory
to the public repository.
- bisect: this is a very useful tool to find the source of
a regression in your code, when a previous version was working correctly
but the tip of the branch isn't working any more.
- blame: more colorful name for what other programs call
annotate. It shows a file adding annotation to each line
listing author, date, SHA1 for the commit. With git blame you
can immediately find the who and when for a specific feature, the SHA1
helps you getting the complete commit log and retrieve the why as
well.